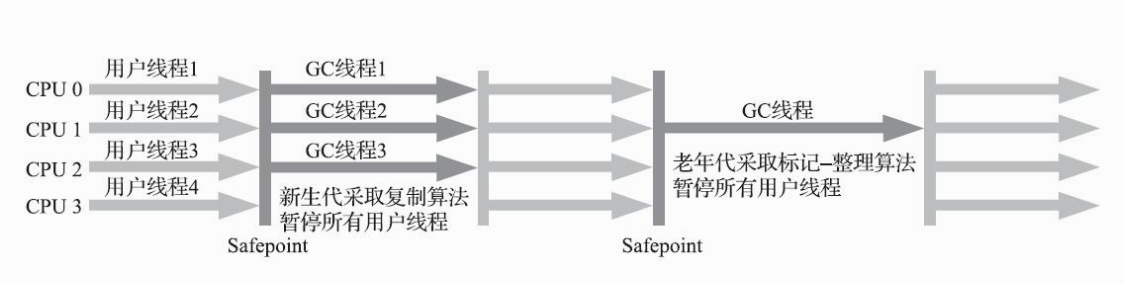
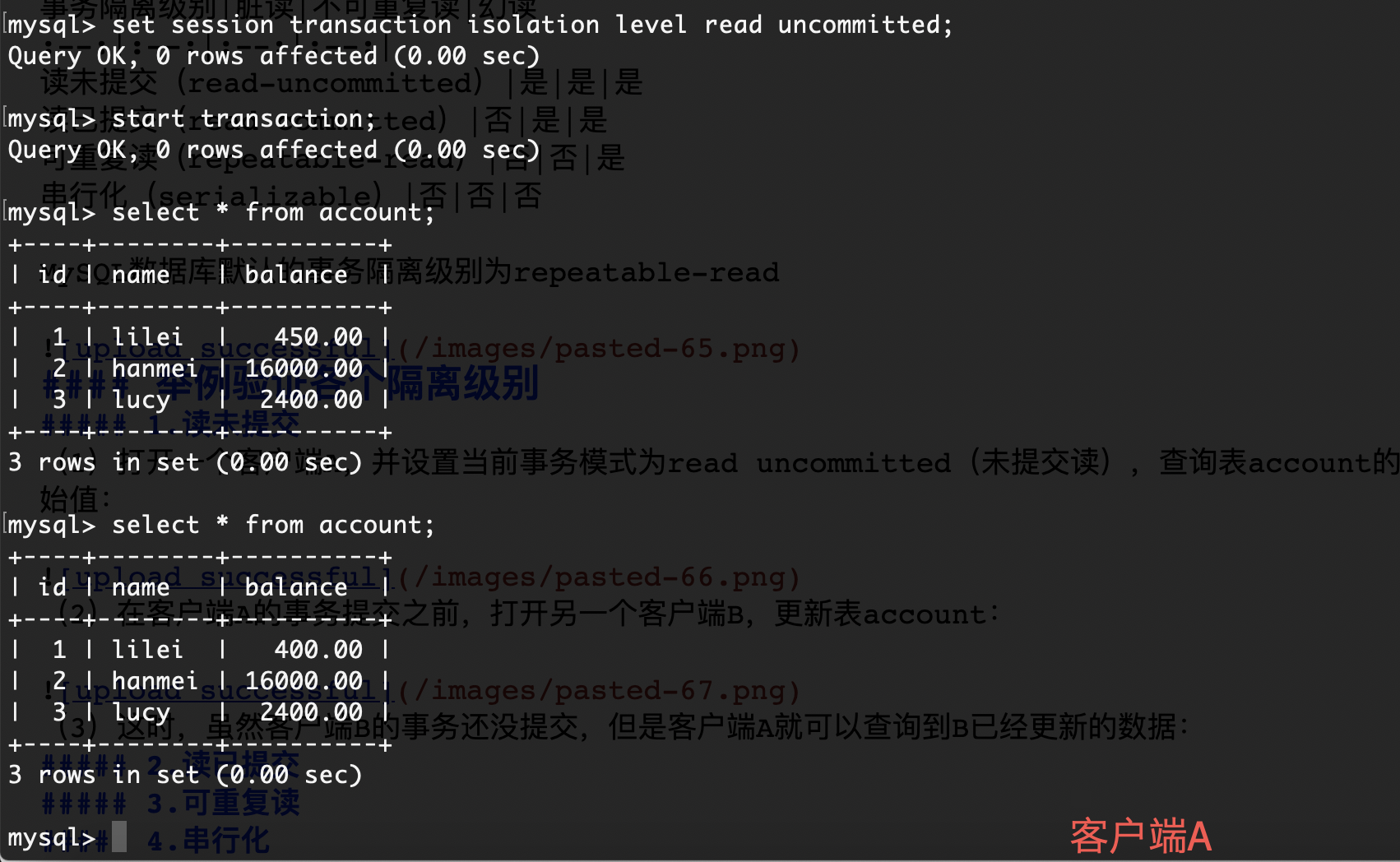
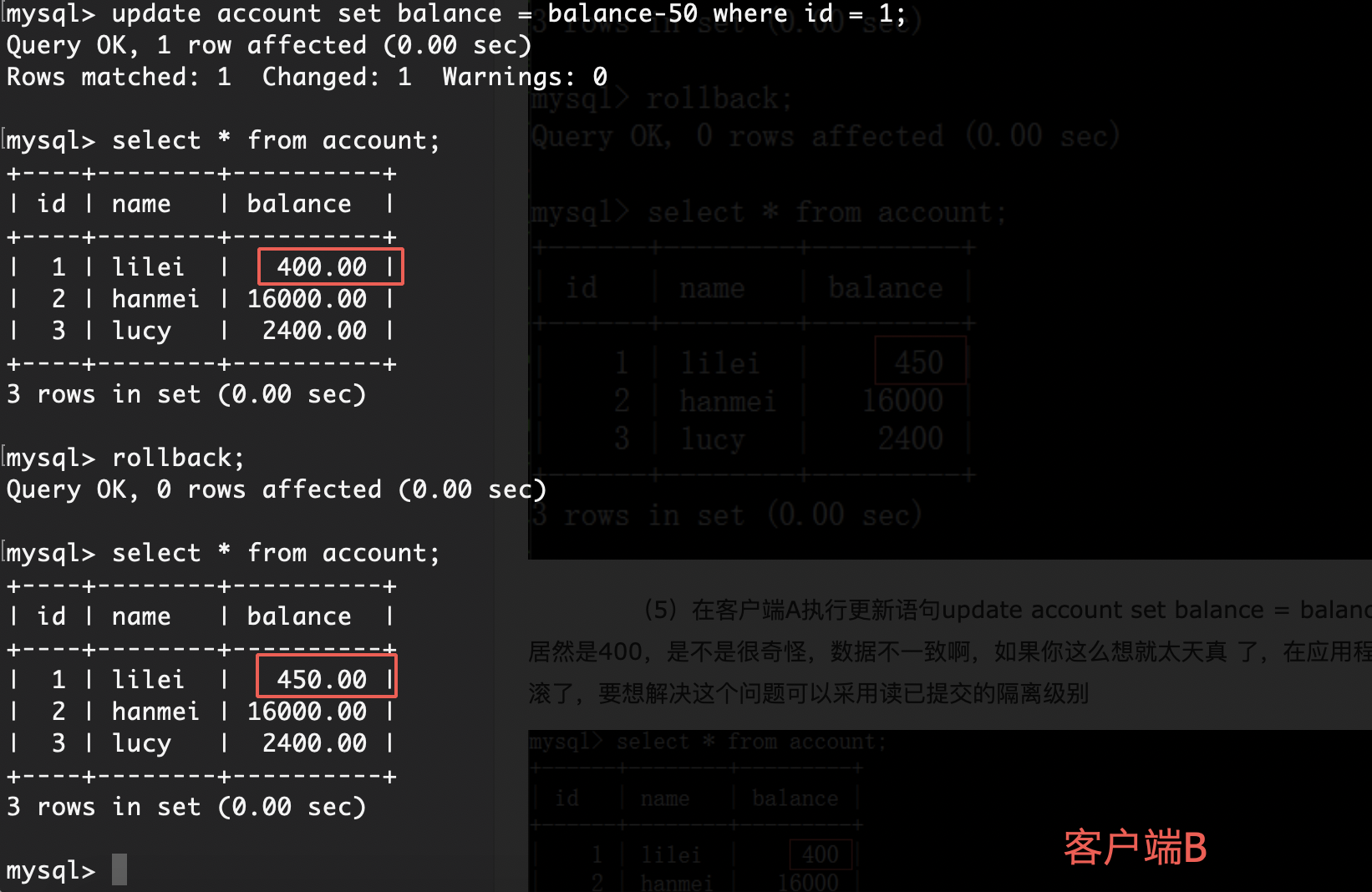
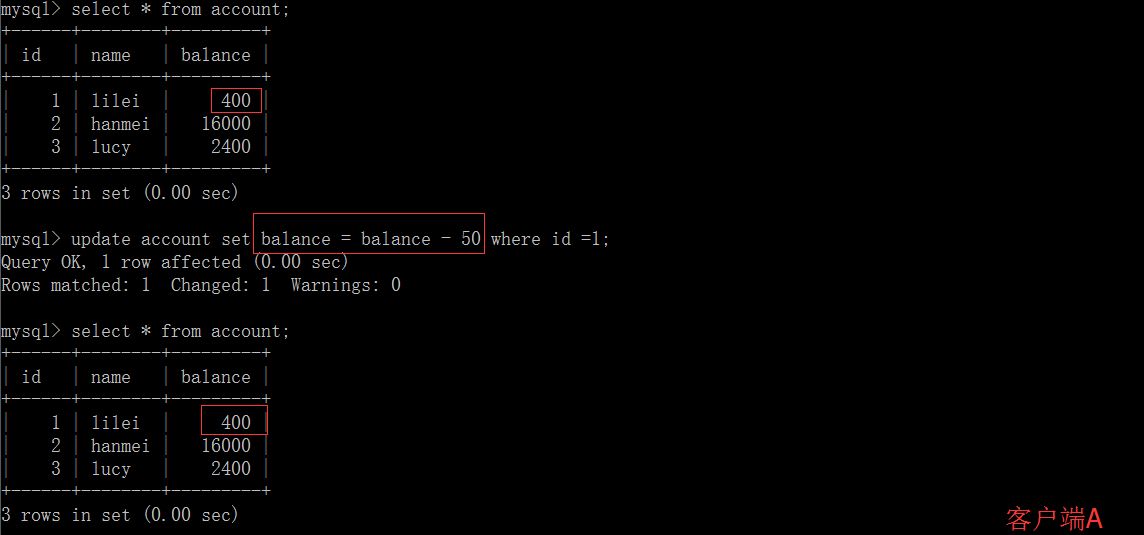
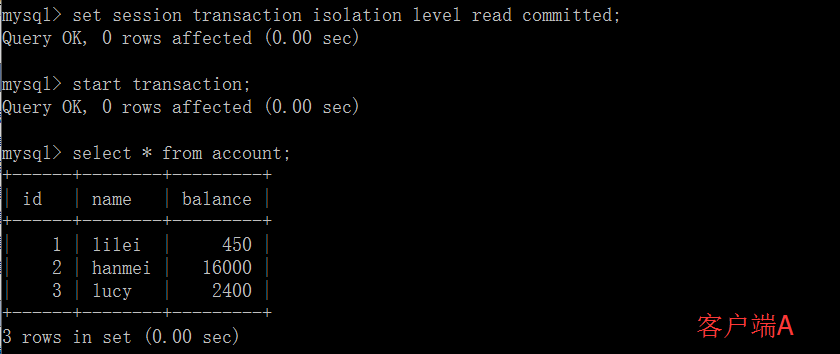
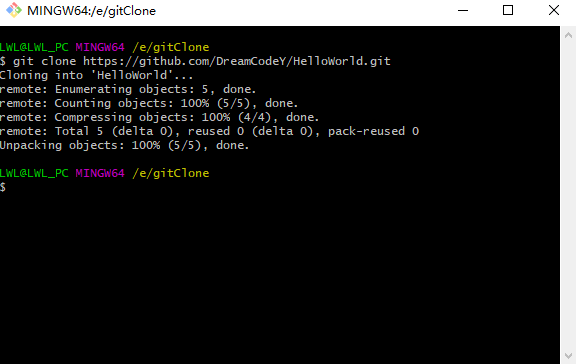
B-Tree
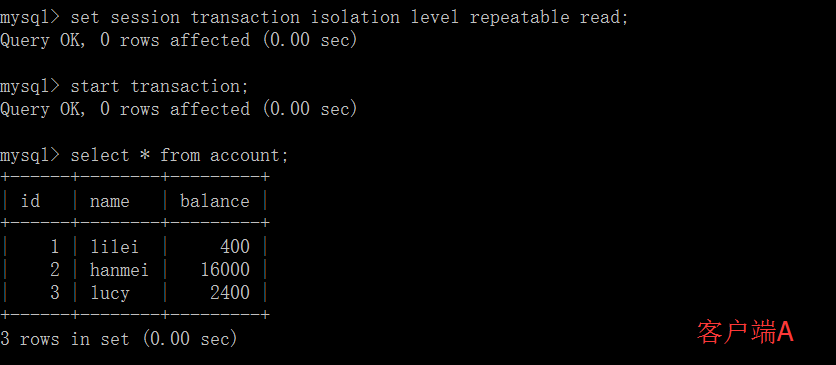
在计算机科学中,B树(B-Tree)是一种自平衡的树,能够保持数据有序.这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数(logN)时间内完成.B树,概括来说是一个一般化的二叉查找树,一个结点可以拥有2个以上的子节点(注意,二叉树每个节点最多只有两个子节点).与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘,B树减少定位记录时所经历过的中间过程,从而加快存取速度.B树这种数据结构可以用来描述外部存储,这种数据结构常被应用于数据库和文件系统的实现上.
B-Tree运用的理念
- 保持键值有序,以顺序遍历
- 使用层次化的索引来最小化磁盘读取
- 使用不完全填充的块来加速插入和删除(减少平衡操作)
- 通过优雅的遍历算法来保持索引平衡
B-Tree的弊端
- 除非完全重建数据库,否则无法改变键值的最大长度
B-Tree的一些术语
定义
一个m阶的B树是一个有以下属性的树
1.每一个节点最多有m个子节点
2.每一个非叶子节点(除根结点)最少有[m/2]个子节点
3.如果根节点不是叶子节点,那么它至少有两个子节点
4.有k个子节点的非叶子节点拥有k-1个键
5.所有叶子节点都在同一层
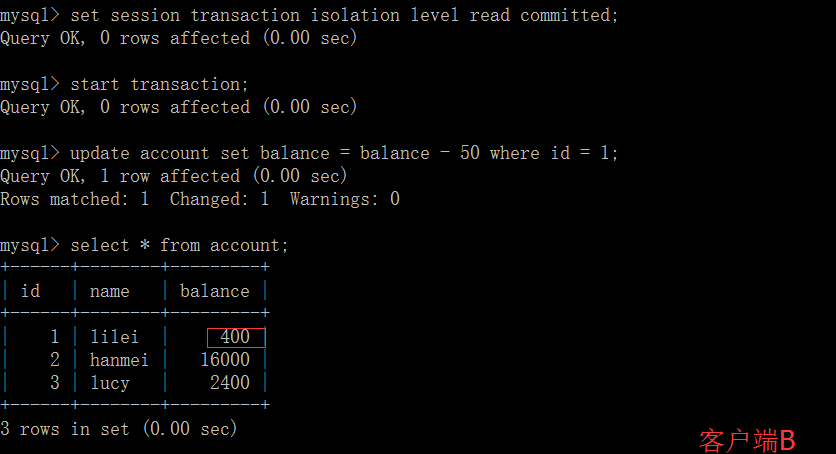
每一个内部节点(非叶子节点)的键将节点的子树分开.例如,如果一个内部节点有3个子节点(3个子树),那么它就必须有两个键:a1和a2.左子树的所有值都必须小于a1,中间子树的所有值都必须在a1和a2之间,右边子树的所有值都必须大于a2.
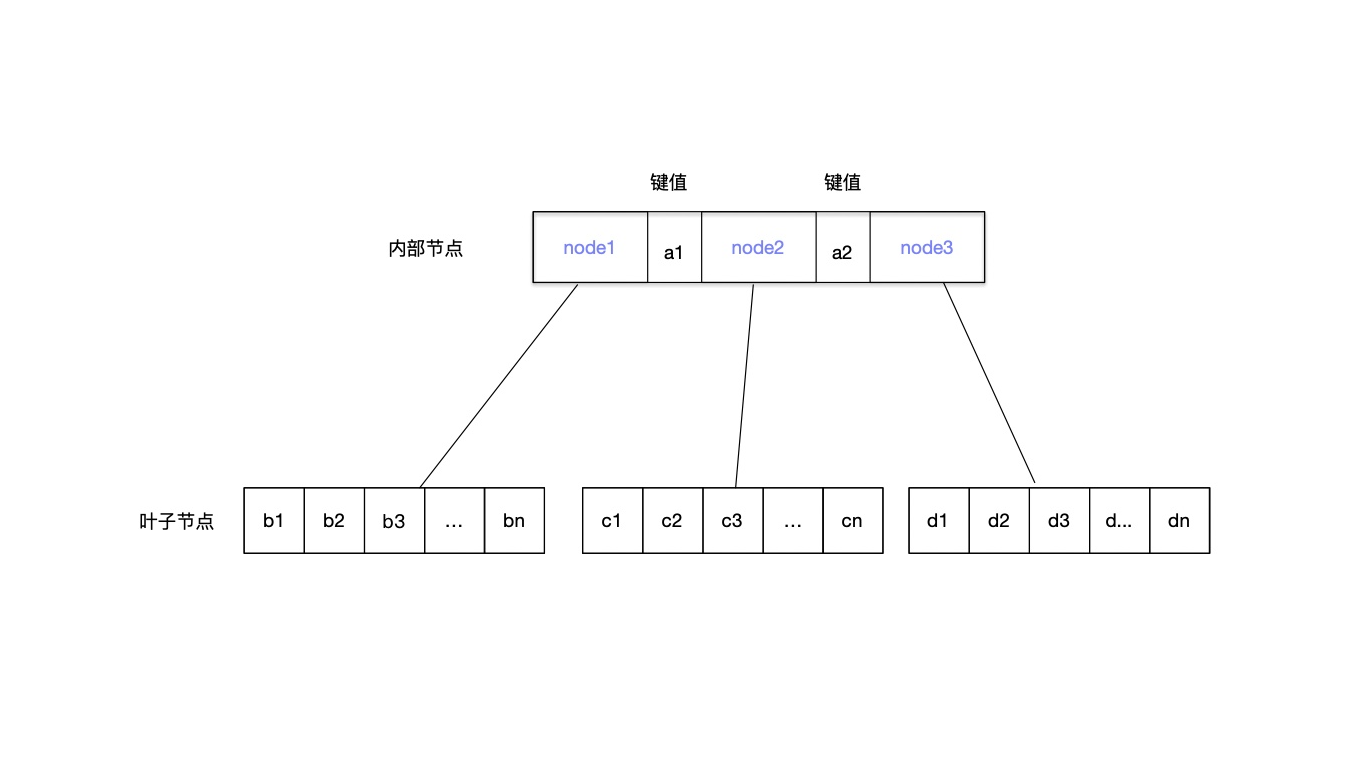
上图是一个n阶B树的一部分,其中叶子节点最多有n个结点,内部节点(非叶子节点)有3个子节点,2个k键.node1指向的子树中,b1-bn所有值都小于a1,node2指向的子树中,c1-cn所有值都介于a1和a2之间,node3指向的子树中,d1-dn所有值都大于a2.
内部节点
内部节点是除根结点和叶子结点之外的所有节点.它们通常被表示为一组有序的元素和指向子节点的指针.每一个内部节点拥有最多U个,最少L个子节点.元素的数量总是比子节点的数量少一(元素的数量在 L-1 和U-1之间),U必须等于2L或者2L-1;因此,每一个内部节点都至少是半满的.U和L之间的关系意味着两个半满的节点可以合并成一个合法的节点,一个全满的节点可以被分成两个合法的节点(如果父节点有空间容纳移来的一个元素).这些特性使得在B树中删除或插入新的值时可以调整树来保持B树的性质.
根节点
根节点拥有子节点数量的上限和内部节点相同,但是没有下限.例如,当整个树中的元素数量小于L-1时,根节点是唯一的节点并且没有任何子节点.
叶子节点
叶子节点对元素的数量有相同的限制,但是没有子节点,也没有指向子节点的指针.
算法
搜索
B树的搜索和二叉搜索树类似。从根节点开始,从上到下递归的遍历树。在每一层上,搜索的范围被减小到包含了搜索值的子树中。子树值的范围被它的父节点的键确定。
插入
所有的插入都从根节点开始。要插入一个新的元素,首先搜索这棵树找到新元素应该被添加到的对应节点。将新元素插入到这一节点中的步骤如下:
1.如果节点拥有的元素数量小于最大值,那么有空间容纳新的元素。将新元素插入到这一节点,且保持节点中元素有序。
2.否则的话这一节点已经满了,将它平均地分裂成两个节点:
(1) 从该节点的原有元素和新的元素中选择出中位数
(2) 小于这一中位数的元素放入左边节点,大于这一中位数的元素放入右边节点,中位数作为分隔值。
(3) 分隔值被插入到父节点中,这可能会造成父节点分裂,分裂父节点时可能又会使它的父节点分裂,以此类推。如果没有父节点(这一节点是根节点),就创建一个新的根节点(增加了树的高度)。
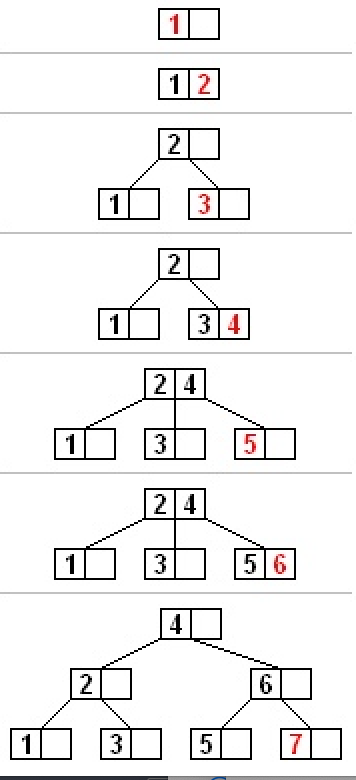
如果分裂一直上升到根节点,那么一个新的根节点会被创建,它有一个分隔值和两个子节点。这就是根节点并不像内部节点一样有最少子节点数量限制的原因。每个节点中元素的最大数量是 U-1。当一个节点分裂时,一个元素被移动到它的父节点,但是一个新的元素增加了进来。所以最大的元素数量 U-1 必须能够被分成两个合法的节点。如果 U-1 是奇数,那么 U=2L ,总共有 2L-1 个元素,一个新的节点有 L-1 个元素,另外一个有 L 个元素,都是合法的节点。如果 U-1 是偶数,那么 U=2L-1,总共有 2L-2 个元素。 一半是 L-1,正好是节点允许的最小元素数量。
删除
有两种常用的删除策略
- 定位并删除元素,然后调整树使它满足约束条件;
- 从上到下处理这棵树,在进入一个节点之前,调整树使得之后一旦遇到了要删除的键,它可以被直接删除而不需要再进行调整
B+Tree
B+Tree是一种数据结构,通常用于数据库和操作系统的文件系统中.B+Tree的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数(logN)时间复杂度.B+Tree元素自底向上插入,这与二叉树相反.