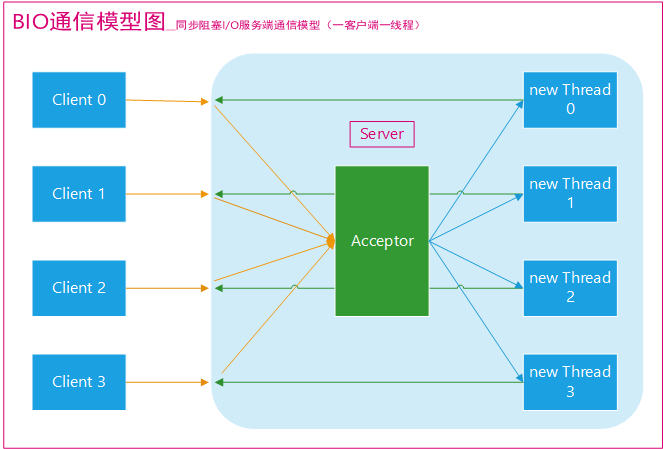
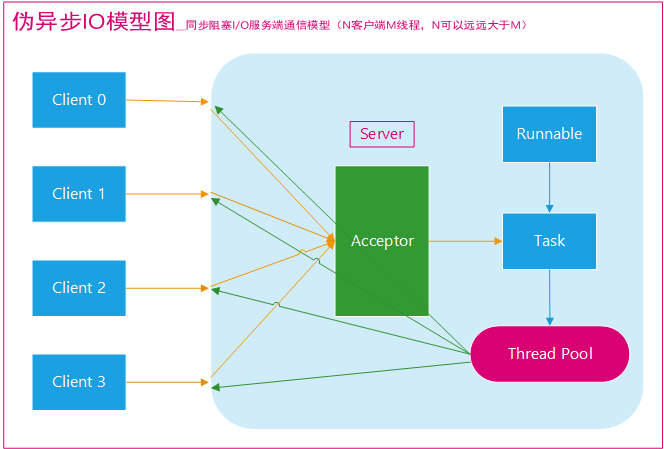
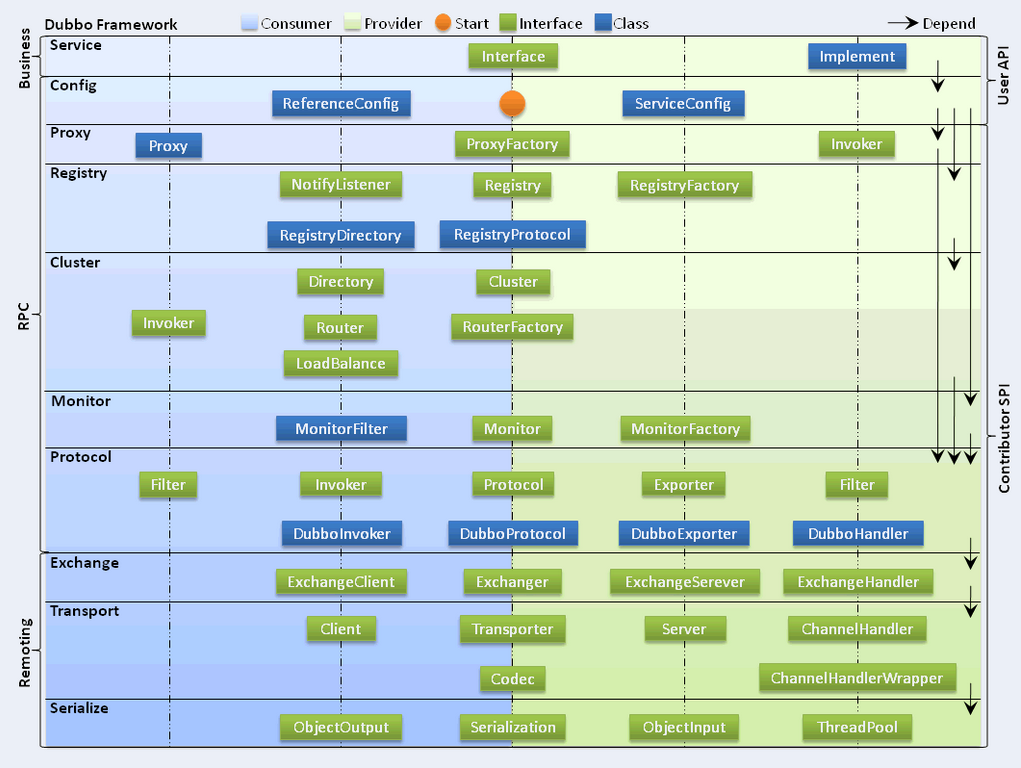
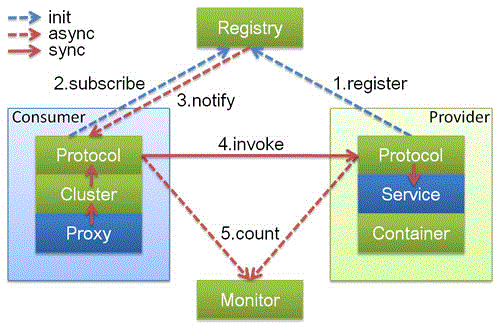
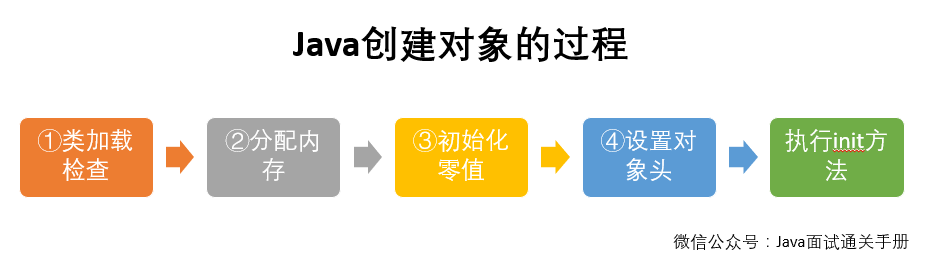
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof Reading from C:\Users\SnailClimb\Desktop\heap.hprof... Dump file created Sat May 04 12:30:31 CST 2019 Snapshot read, resolving... Resolving 131419 objects... Chasing references, expect 26 dots.......................... Eliminating duplicate references.......................... Snapshot resolved. Started HTTP server on port 7000 Server is ready.
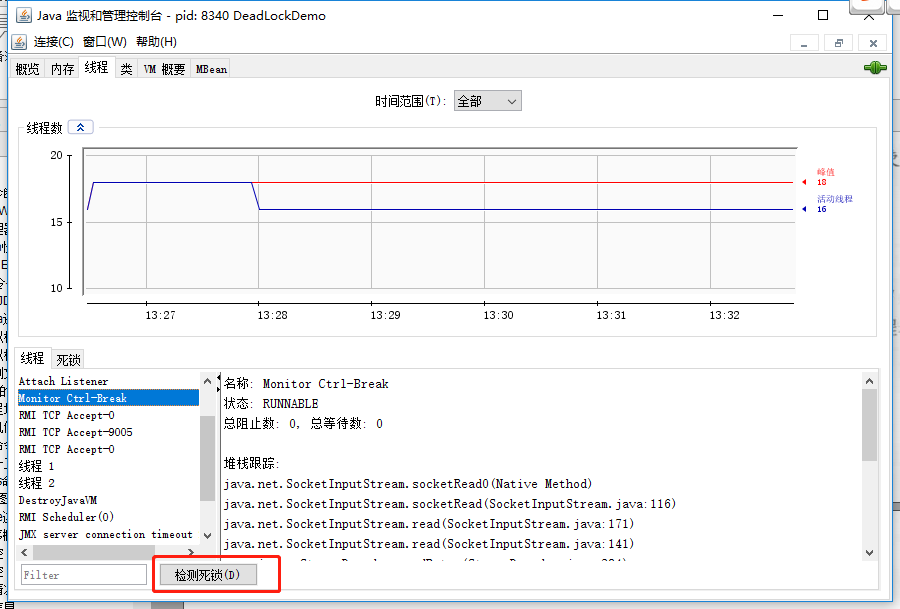
Thread[线程 1,5,main]get resource1 Thread[线程 2,5,main]get resource2 Thread[线程 1,5,main]waiting get resource2 Thread[线程 2,5,main]waiting get resource1
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
Found one Java-level deadlock: ============================= "线程 2": waiting to lock monitor 0x000000000333e668 (object 0x00000000d5efe1c0, a java.lang.Object), which is held by "线程 1" "线程 1": waiting to lock monitor 0x000000000333be88 (object 0x00000000d5efe1d0, a java.lang.Object), which is held by "线程 2"
Java stack information for the threads listed above: =================================================== "线程 2": at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31) - waiting to lock <0x00000000d5efe1c0> (a java.lang.Object) - locked <0x00000000d5efe1d0> (a java.lang.Object) at DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) "线程 1": at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16) - waiting to lock <0x00000000d5efe1d0> (a java.lang.Object) - locked <0x00000000d5efe1c0> (a java.lang.Object) at DeadLockDemo$$Lambda$1/1324119927.run(Unknown Source) at java.lang.Thread.run(Thread.java:748)
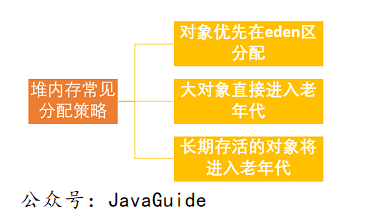
老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
测试:
1 2 3 4 5 6 7 8
public class GCTest {
public static void main(String[] args) { byte[] allocation1, allocation2; allocation1 = new byte[30900*1024]; //allocation2 = new byte[900*1024]; } }
通过以下方式运行:
添加的参数:-XX:+PrintGCDetails
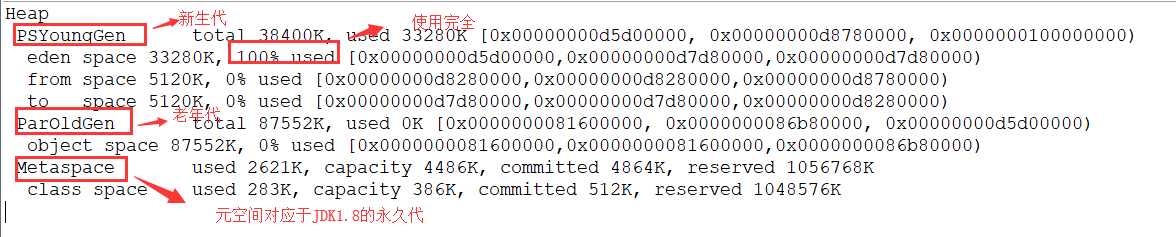
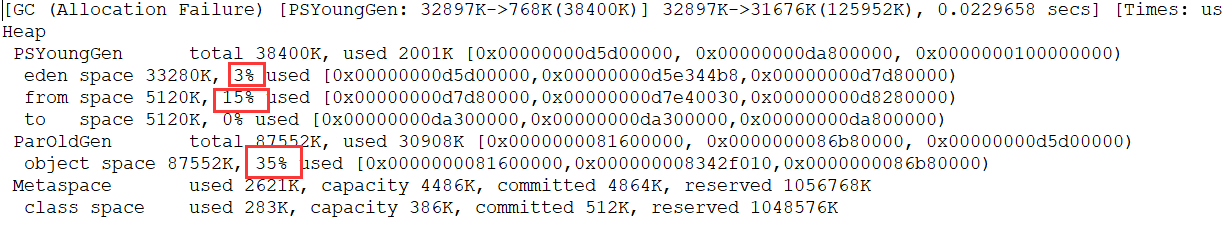
运行结果 (红色字体描述有误,应该是对应于 JDK1.7 的永久代):
从上图我们可以看出 eden 区内存几乎已经被分配完全(即使程序什么也不做,新生代也会使用 2000 多 k 内存)。假如我们再为 allocation2 分配内存会出现什么情况呢?
1 2
allocation2 = new byte[900*1024];
简单解释一下为什么会出现这种情况: 因为给 allocation2 分配内存的时候 eden 区内存几乎已经被分配完了,我们刚刚讲了当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.GC 期间虚拟机又发现 allocation1 无法存入 Survivor 空间,所以只好通过分配担保机制把新生代的对象提前转移到老年代中去,老年代上的空间足够存放 allocation1,所以不会出现 Full GC。执行 Minor GC 后,后面分配的对象如果能够存在 eden 区的话,还是会在 eden 区分配内存。可以执行如下代码验证:
1 2 3 4 5 6 7 8 9 10 11
public class GCTest {
public static void main(String[] args) { byte[] allocation1, allocation2,allocation3,allocation4,allocation5; allocation1 = new byte[32000*1024]; allocation2 = new byte[1000*1024]; allocation3 = new byte[1000*1024]; allocation4 = new byte[1000*1024]; allocation5 = new byte[1000*1024]; } }
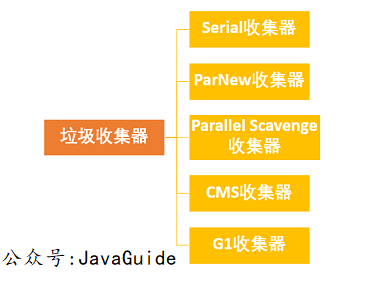
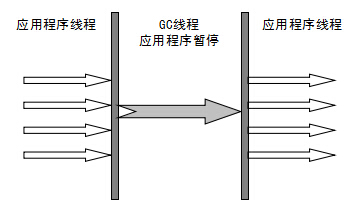
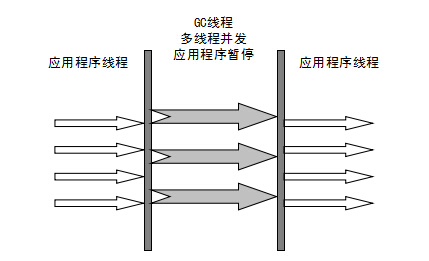
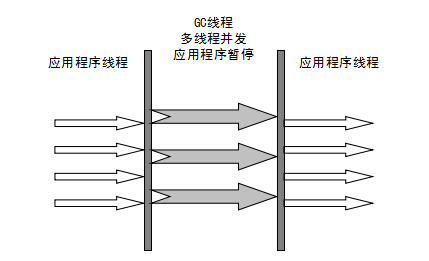
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程垃圾收集器了。它的“单线程”的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程(“Stop The World”),直到它收集结束。
/** *此方法将始终缓存-128到127(包括端点)范围内的值,并可以缓存此范围之外的其他值。 */ public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
应用场景: 1.Integer i1=40;Java 在编译的时候会直接将代码封装成Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。 2.Integer i1 = new Integer(40);这种情况下会创建新的对象。
1 2 3
Integer i1 = 40; Integer i2 = new Integer(40); System.out.println(i1==i2);//输出false
Integer比较更丰富的一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13
Integer i1 = 40; Integer i2 = 40; Integer i3 = 0; Integer i4 = new Integer(40); Integer i5 = new Integer(40); Integer i6 = new Integer(0);